I’m working on a big project. I’m creating a complex object and its molds directly with grasshopper.
I cannot post the definition…
Almost everything is parametrized.
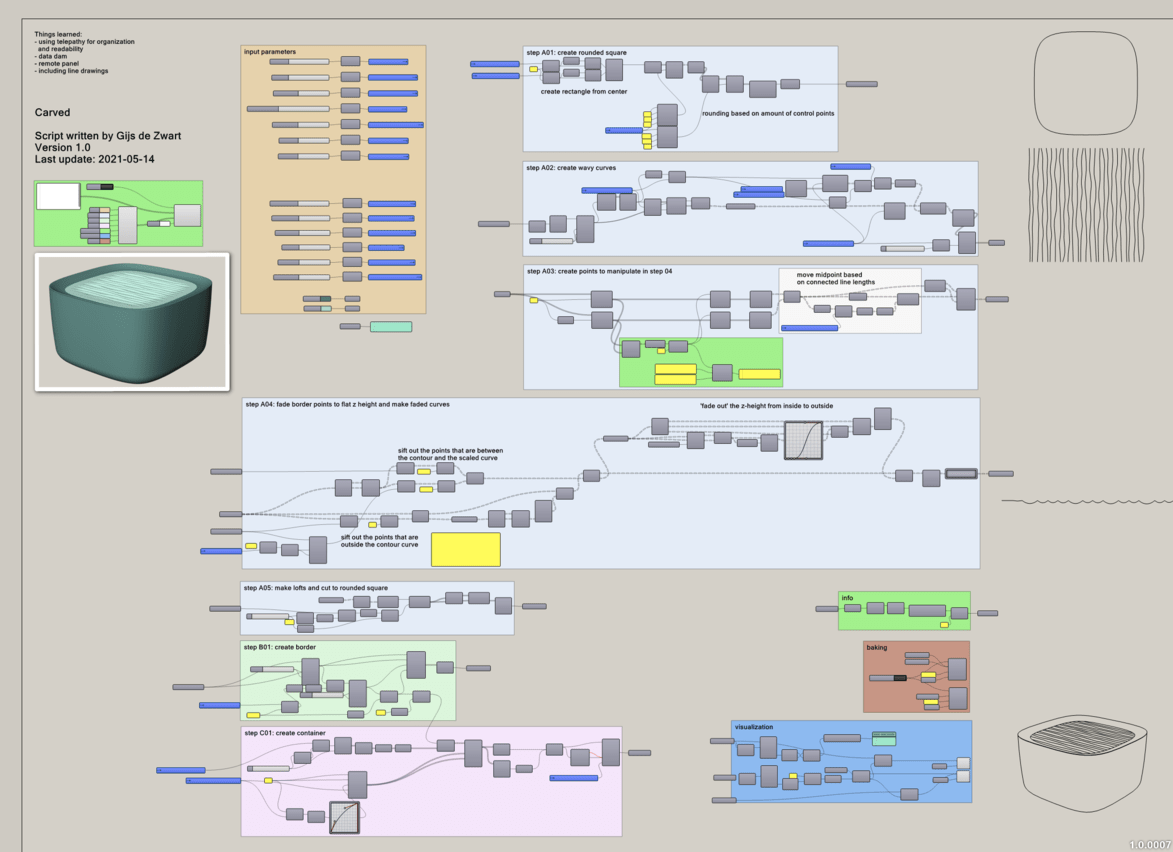
As I want each user interaction to be decently smooth, I’ve divided the definition in “steps”.
Each step have its own parameters, message/warning panels, geometry previews and outputs.
While the step is “on edit” the previews will be enabled, and all the subsequent steps will be completely disabled.
When the step is “completed” the previews will be disabled and the next step is enabled.
I’ve used a small c# to enable/disable whole chunks of code and “Stream gate” do block the flow of data.
Above the steps I’m using an “array” of global geometries that are changed and added at each step.
I would use clusters to “pack” the definition, to make it better looking and to give a more ordinate feeling to everything, but I can’t manage and use custom previews if inside a cluster, breaking all the logic I’ve made.
How… would you make this situation better?
Did you ever had a similar situation? How did you solve it?
Hi, @maje90 Actually, your definition looks really organized, maybe with entwine and explode tree to clearly break the steps?
Could you share your enable-disable-group C# please, it looks really helpful
thanks for sharing your workflow!
Dear @maje90
(my english is not better then yours ;-D, no reason to excuse)
For a longer perspective i recommend to start programming rhino-Plug-ins with Visual Studio, using Rhino Common and skip grasshopper. To get live-update you can use display conduits while a command is running - and asking the user for stepwise input. Or have geometry with custom data, … many concepts are possible…
I think there is a certain size of grasshopper-Definition, where the benefit of the low threshold to access the technology via visual programming is no longer justified in comparison to text based, object orientated, type save programming. (with harder start, less visual, but much more tools to organise code and readability, much stronger approaches to organise data and logic)
I am looking forward to see, how other users suggest to structure this big definitions.
Regarding this aspect i love this topic:
sorry for not having a short term solution / answer. kind regards -tom
Yeah, Clusters are a good way to organize. They essentially split one big definition into smaller ones. One can even save each cluster as a separate file / UserObject. Also, I believe we can also view the preview from outside, if we enable Preview Contents from the context menu.
This is OT, but an interesting argument.
Also, i’m not sure I can agree.
The code in the video is the work of something like 8 full days.
I’m pretty sure doing all of this in a single (or splitted) text code would have taken way more time than this.
And that make the difference from picking and doing the job or not.
Generally, is text based code faster and cleaner compared to visual programming, disregarding time and effort? Yes.
But if you have “low” budget and/or time, visual programming lets you achieve incredible stuff anyway.
If I had to do this job with text code, I would have declined it.
Literally a thousand objects.
But again, this is OT.
Swapping to text code would be a realistic solution with 10x the budget I have, imho.
thank you @maje90, I really appreciate it, I was wondering if with the same logic true/false a C# could change only the colour of the group that belongs to, I saw examples but those require a group name and your analysis is so clean, I’d like to implement this idea inside a code, so any help I’d appreciate it,
Good luck with your project and hope you post your final workflow!
Regards!
T.
This is very interesting topic! Thank you for starting it and sharing the video!
Shapediver has some nice tips on managing definitions, big and small.
Marking: grouping components, naming the groups, and using color system for different groups (input, output…). Using “Hidden” wires, “relays” and clusters to have a cleaner overview of the definition.
In this way each definition becomes a template file of a sort.
Splitting definition to smaller chunks.
By looking at your video I see that you already implemented majority of these points, so sorry if my comment was not of much help.
I am just curious, what does your definition create? What is the final product?
Thank you for the reply.
I also like to have distinct steps with clear inputs and outputs. The shapediver link is a very good example. I have been preparing files for a training and they look like this:
@ThomasE
This c# disable group.gh (14.4 KB) (edited) is similar to previous, but with a cleaned up method to find the group, and then the same method used to apply the color to the group of the c# itself, one of its sources or one of its recipients:
@djordje the tips from Shapediver make sense, but imo are useful just for small definitions with “few” parameters.
In my situation i am forced to divide the work into steps because 1- computing time would be too much (stuttering silders, choppy feels, etc) and 2- the previews would be overlapping: many construction geometries are shown while editing them, but are not actual part of the final model… it would result in a “clusterf***” of colored stuff on display.
And, I’m sorry, but I cant disclose what the product is. It is already much that I showed part of the code on the video (but it would be impossible to copy any of it due to clusters and scripts…)
@Gijs You have distinct steps!? Are those steps depending each-other? (meaning you need to complete one before the next make sense / is correct).
How do you solve the overlapping previews? How do you turn them on/off at the correct time?
Is there any reason you aren’t splitting the code into several GH files using Data Output and Data Input? Some of its so-called disadvantages might address the issues of “light” code blocks with limited downstream impact and isolated geometry previews.
Main reason is because the code is not completed yet, so it happens very often that I need some number/geometry from in-between a previous step to work on another step.
Editing it all by swapping different files would slow things down, for now.
I’m not sure I have “light” code blocks, as said, be it clusters, hops, or other files using output/input, each block will load dozens of parameters and output something similar.
By the way, i almost never used Data output and input … what’s the gain over a cluster?
Also, wouldn’t that need to have the user swap to different grasshopper files to work?
When you modify an earlier step, your changes won’t affect later steps until you edit those GH files so there is no downstream code burden. That’s what I meant by “light” code blocks.
Two caveats:
If you have a five step process (for example), and modify Step #2, each of the subsequent steps must be opened (activated) in sequence to fully propagate your changes.
Removing params from Data Output or inserting new params anywhere except the end of the existing list will cause a wiring snafu for the corresponding Data Input. There is a safe procedure to do that using data file version numbers and care about moving wires from the old Data Input to a new one.
It has worked well for me.
P.S. A huge advantage I forgot to mention is that the ‘.ghdata’ files used by Data Out/Input are persistent so don’t need to be re-computed each time you work on a downstream “step”.
My biggest project has at least seven GH models communicating via Data Output and Data Input and I can spend days or weeks working on a later step without having to touch any earlier code. This also makes it easier to know what parts of the code changed, which is another weak point about GH, compared to traditional text programming.
Your solution really have many good points!
I need to consider it with the final customer…
It all need to be something where a “casual” grasshopper user will not be lost.
Being able to break a large GH model into pieces was one of the R6 features that interested me most.
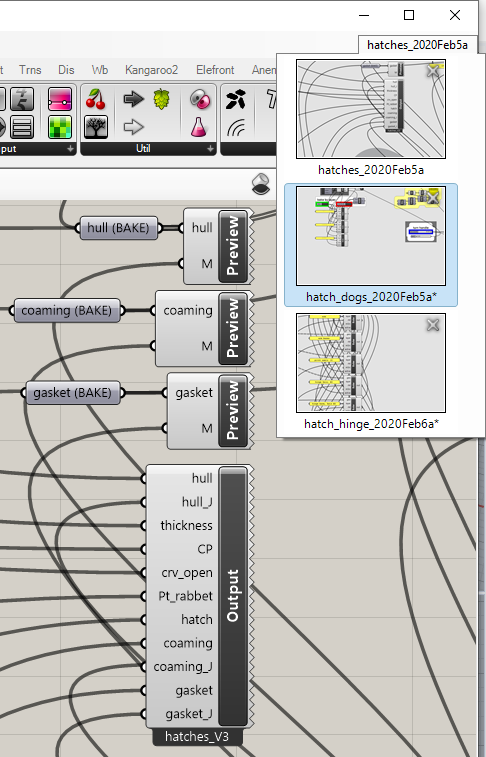
I made this demo of a three step model almost two years ago: ghData_IO.zip (446.0 KB)
hatches_2020Feb5a.gh offers choice of ‘Construction Plane’ (XY, XZ, YZ or a custom plane), ‘Shape’ (Ellipse, Rectangle, Custom) and a slider to ‘Open’ the hatch, along with many params to set dimensions. Generates file hatches_V3.ghdata
hatch_dogs_2020Feb5a.gh adds a handle in the middle of the hatch to turn “dogs” around the edge to latch it closed. Again, there are many other dimension parameter sliders related to this specific “step”. Generates file hatch_dogs_V2.ghdata
hatch_hinge_2020Feb6a.gh adds an elaborate two-part hinge and a ‘swing_open’ slider that moves the hatch, handle, “dogs” and hinges (there are two!) appropriately. As in the earlier steps, there are many additional dimension parameters specific to this step.
It’s a rather elaborate model that has nothing to do with the bigger project I mentioned, but it’s enough to see how Data Output and Data Input work, including the limitation that you can’t turn the “dog handle” and swing the hinge at the same time (because the sliders are in separate GH files)…
Aye, there’s the rub! That’s a challenge. Ultimately, the Shapediver approach makes sense.