I’ve got one script sitting at 2725 objects, would be interesting to see how that stacks up!

3 Likes


15 Likes
Dear lord, that is one big ball of mud 
4 Likes
Yeah - I agree - that looks like a hard one to trouble shoot Lukasz. I think I would have given up on my 2700+ monster if I hadn’t of been really disciplined on the layout and packaging of my various sub-routines.
Same file without the hidden wires showing.

2 Likes

The size is one thing, but damn, it isn’t even organised left-to-right…
3 Likes
You haven’t seen my desk!
But jokes aside I know it doesn’t look very tempting to troubleshoot but I’ve been working on this for about 3 years now and I’ve been adding functionality I wasn’t even planning to do in the first place. I know every dark corner of this script as I constantly work with it on a daily basis but true…it looks like pure mess. Whenever I’ll be done with full concept I’ll be planning full re write to python.
1 Like
what does it do? Same question to you @kiteboardshaper
4 Likes
Hi TomTom,
Mine is a parametric engine for designing inflatable type kitesurfing kites and unrolling/marking up all the panels ready to cut from the fabric:


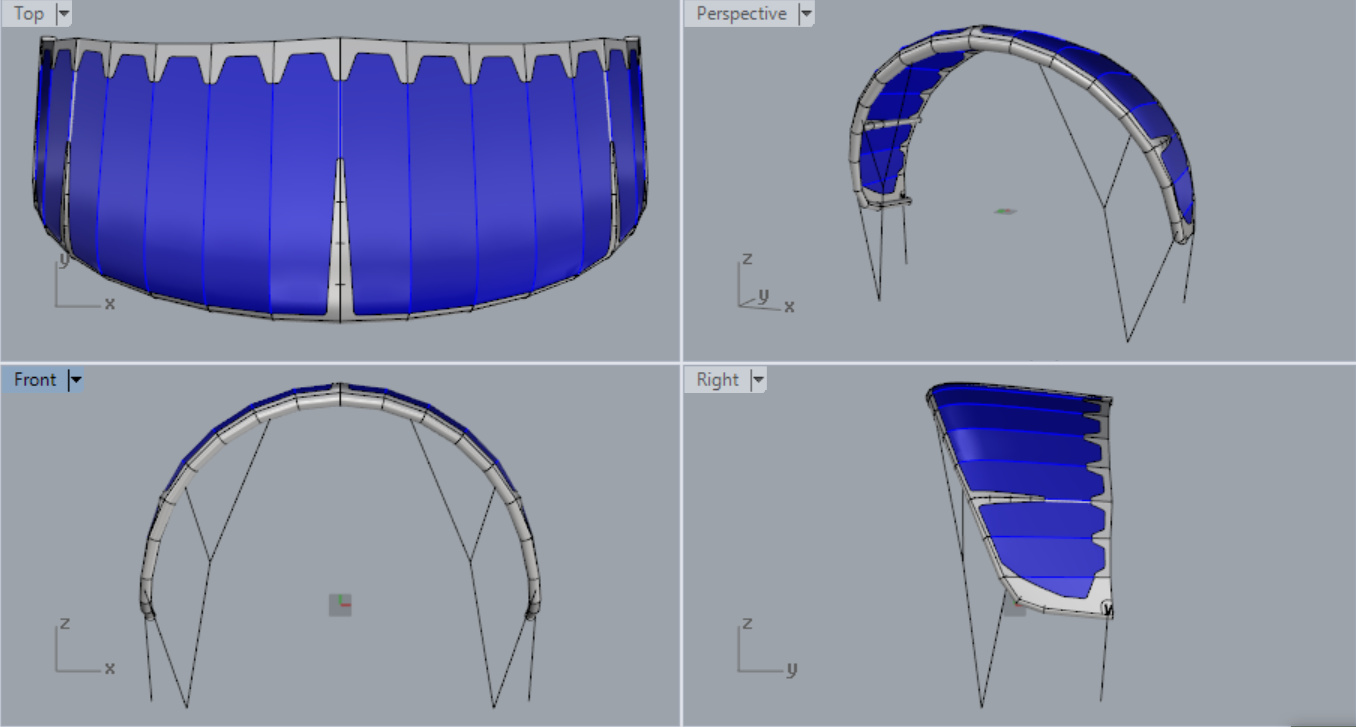
35 Likes
It generates geometry for jewellery for manufacturing and also geometry for rendering based on gem certificate number (about 10 different designs)
Places all the detail into our stocking system
Places all info to our website
Does all price estimate
Makes 3d low poly version for web
Sends geometry to render
And few other functions…

Some samples all within seconds

34 Likes

awesome scripts!
Unfortunate my largest scripts never go beyond 150 due to my personal preference on direct coding.  So in order to compete here I had to make a useless script
So in order to compete here I had to make a useless script
@RIL inspired me 
100003 components 
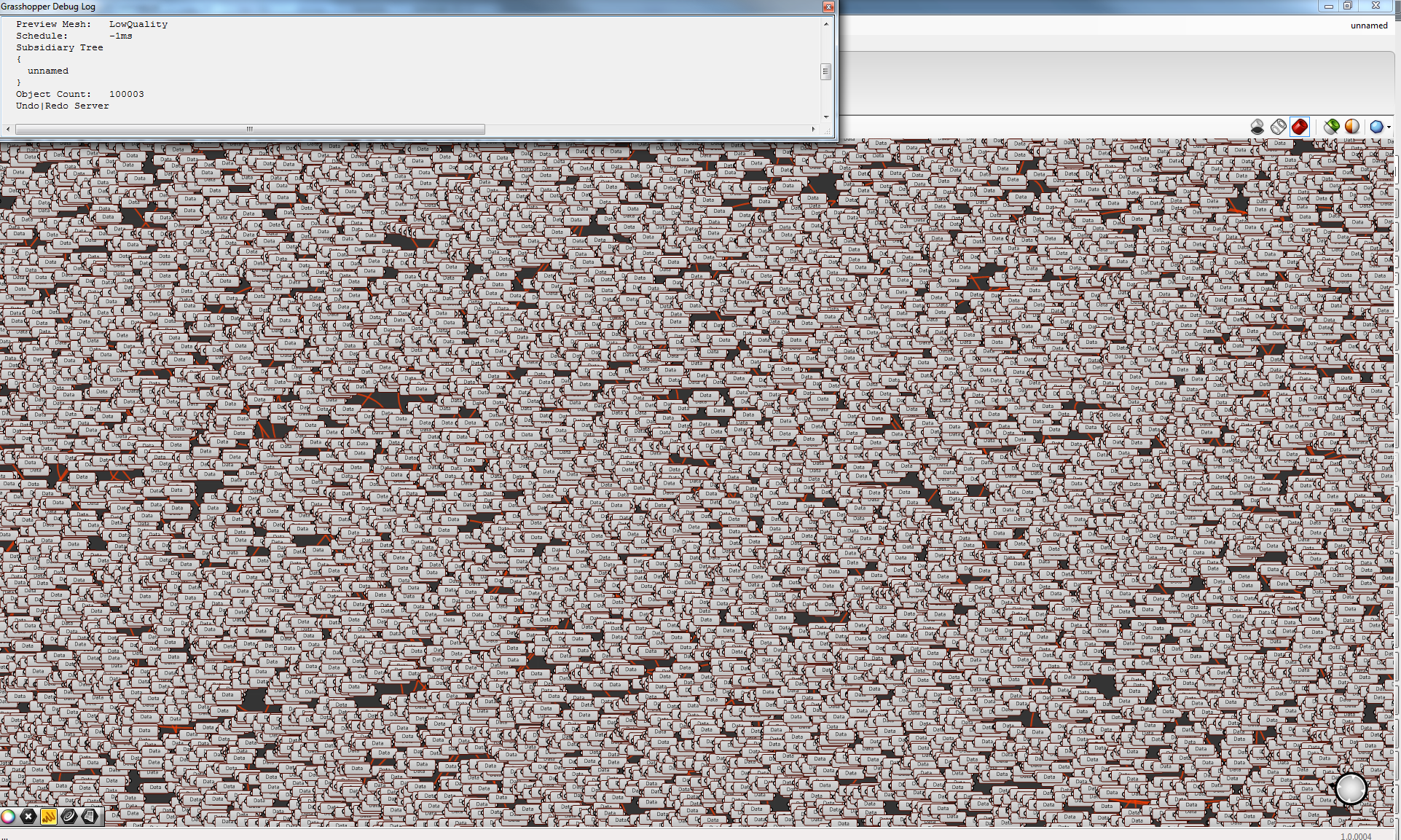
10 Likes
You must be a more efficient coder, mine is at 5160 (which seems high, only looks like 700 or 800); checking document info, I began working with it in 2013 as something that was just going to be a quick a idea. A tweak here, a tweak there, and it is still evolving.
Which leads me to a curiosity question: what do others do? Do you start from scratch for each script, or do you keep evolving one, or you do keep a library of subroutines and then ‘patch and paste’ from your library for each new project? What is considered ‘good’ practice?
I think that what would be very powerful is a kind of “EntoRhino” functionality which can very efficiently connect multiple separate GH definitions so that they can all be simultaneously active in the same session. Then separate definitions could more often be reused for different projects.
// Rolf
(entorhinal cortex is a special kind of “connection hub” which helps organise different regions in the brain)
1 Like
This is what auto graph offers me as an alternative…nice and clean flow left to right ![]()

Again it looks like pure mess but for me it’s pretty “logical” the way it is
3 Likes
But way more cleaner than your first picture 
Is that your „you can’t fire me“-Strategie?
Nobody else can use that file! 
Btw: I really like the result.
3 Likes
It is always logical if it connects logically. GH could have “layers” so that one could stack logic and connect between them as a 3D sandwich. Then related logic would be both located and connected “nearby” each other.
// Rolf
2 Likes
Well first of all we should not compare apples with oranges. Some people solve problems completely within Rhino and Grasshopper. And they can, because their problems allowing them to do this. Good examples are shown above.
In my field of work (automotive) there is a hardly anything I could fully automate. There is simply to much features missing, so I create solutions which support the traditional approach but doesn’t replace them. Not even close.
I also write my own tools, solving very common problems. So I made a whole surface toolset of features missing. On the other hand there is hardly any script where no custom solution is required.
I code for new features, I script to simplify gh definitions.
Component count gets often very big because most components don’t really do much. “List item”, “multiplication” etc … Often you can replace 2 or 3 components with one simple line of code.
I tend to create one custom components for 10-40 components. Not more, not less. If you do more you loose modularity, if you do less you don’t really have any benefit from it.
Regarding how to do a definition:
I personally distinguish between creational and defensive mind-set, which comes from programming. In creational mode I follow no rule of “good” practice nor I care about error,documentation, performance and extensibility. The thinking is: I don’t make any relevant mistakes, I just want to solve the problem, I don’t care if someone else don’t understand what I’m doing. Some people always stop working on it when the problem is solved, but this where the real work actually begins. Same for modelling. You don’t stop when finishing a model. You clean up, improve and simplify.
These problems getting solved in a second step, when being defensive. The thinking is: There is never a perfect definition.
7 Likes
So true. It’s not until you got something working that you actually start to understand the (full extent) of a problem. So a good approach is to “just do it”, and then, as you say, refine it.
If you also need to share a solution with others, then there’s the need for some strategy or structure that can be communicated. This is a weak spot in logical networks. Structure contaning very different levels of logical complexity, is in itself not “explanatory”. Grouping helps, but not even that is always enough.
Named relations (wire ends), for example, is still a missing important feature in GH. (two connections to the same component inport doesn’t always have the same meaning, and often the meaning isn’t clear even for a single connection).
Capturing a diagrams’ meaning and intent on multiple abstraction levels is tricky stuff, but adds real value if a definition is to be shared.
// Rolf
2 Likes
The Kite Design script has been built up over time - and evolves as I need it.
The only ‘best practice’ I think I have picked up is to isolate subroutines as ‘pure functions’ and build these in a way that would allow them to be turned in clusters. I.E:
1/ Data in on the left, Data out on the right - no connections in or out of subroutine mid function.
2/ ALL data passed in and out via NAMED parameters (I generally I use Geo or Num types for this) - no wire attached to a function block is allowed a connection outside of its subroutine
3/ Group and label each subroutine so I know exactly what it does without needing to poke around.
I have no idea if this is the BEST way way of doing things - but it works for me and over time I’ve been able to amend/update/replace various subroutines without needing to trace/rewire 100s of connections.
Cheers
DK
5 Likes