Hey,
I have a problem. I cannot figure out a strategy to cluster points together. Do you know might have an idea about that? What is the most fastest you think?
Thank you for your response ![]()
problem_sortClusters_00.gh (16.4 KB)
Hey,
I have a problem. I cannot figure out a strategy to cluster points together. Do you know might have an idea about that? What is the most fastest you think?
Thank you for your response ![]()
problem_sortClusters_00.gh (16.4 KB)
If I had an hour to solve a problem and my life depended on the solution, I would spend the first 55 minutes determining the proper question to ask, for once I know the proper question, I could solve the problem in less than five minutes.
– Albert Einstein
Hey,
I don’t understand how your points are related to the size values? How do these values correspond to each other?
Are you simply looking to translate what the vanilla components do to GHPython?
What I mean with size values is the sizes of the pointClusters.
So, the size of cluster A must exists out of so many points and be close to cluster B and C. I mean that by size values. 
@Joseph_Oster
To explain myself more clear. I thought several things but all of them ended up in ‘union-like layering.’
In theory, if I would do it by hand, it will be rectangle patterns balanced out by distance to each other or something. Or something with kangaroo.
So, my question is really about what could be the right/best/fastest strategy.
Then maybe I can solve it myself with that parametric strategy.
(I bookmarked your post).
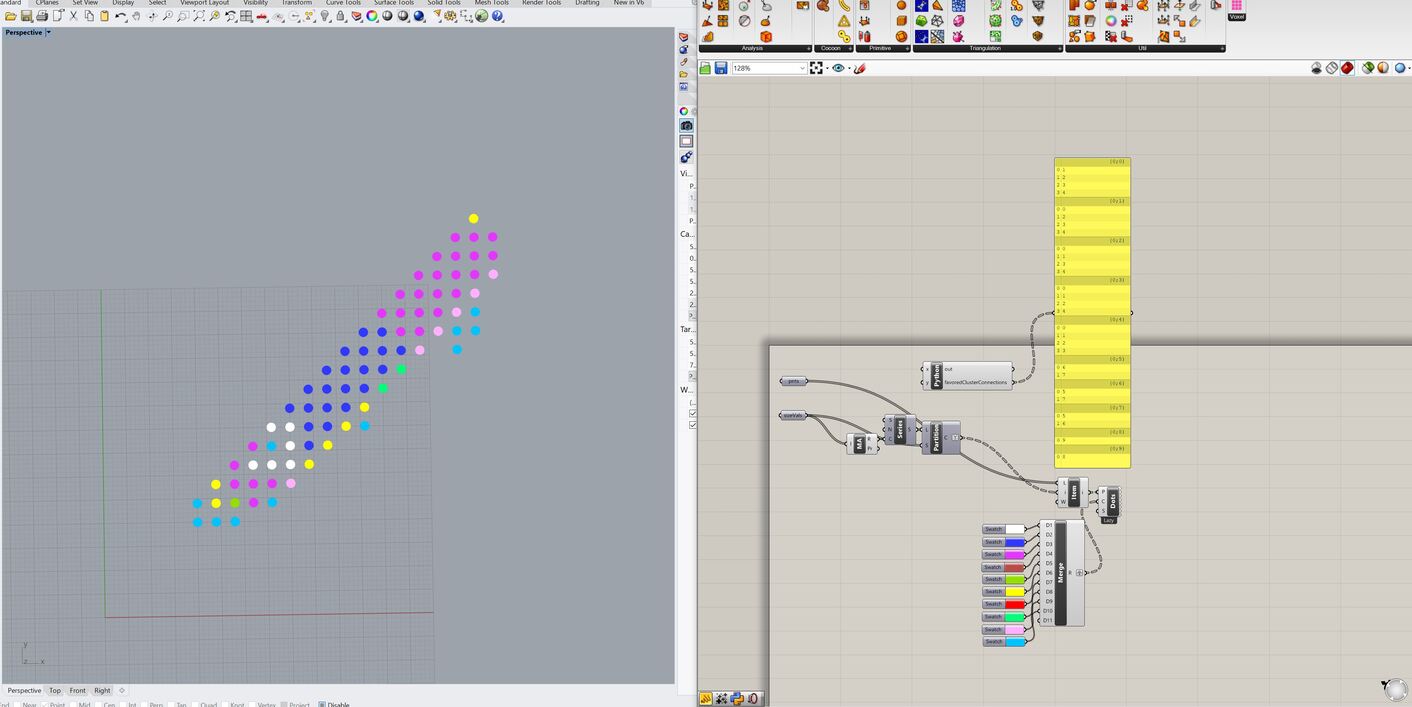
And. Now my yellow points are spread everywhere. I could start with points or with dissecting things. But, all my approaches seem to have death ends.
So. How can I group the points based on size to clusters and how to sort the clusters to its ‘favoredOtherClusters?’
Keep iterating on the Einstein quote, your “problem statement” is still very far from clear.
What is the point of having ‘sizeVals’ = 0? Two of them.
I’m inclined to suggest Closest Points (CPs) but really don’t know if it applies here? This is probably not what you have in mind?
Nonsense, of course. GIGO (Garbage In, Garbage Out) applies to questions as well as data.
You wanted to try to show me a direction (which I asked for) or did you mean this as the answer?
I was thinking about things with closest points but failed.
My setup will exists out of many more points and many levels.
I was thinking of starting at the edge by when things would be more diverse. The following is just one layer of the many I will work with.
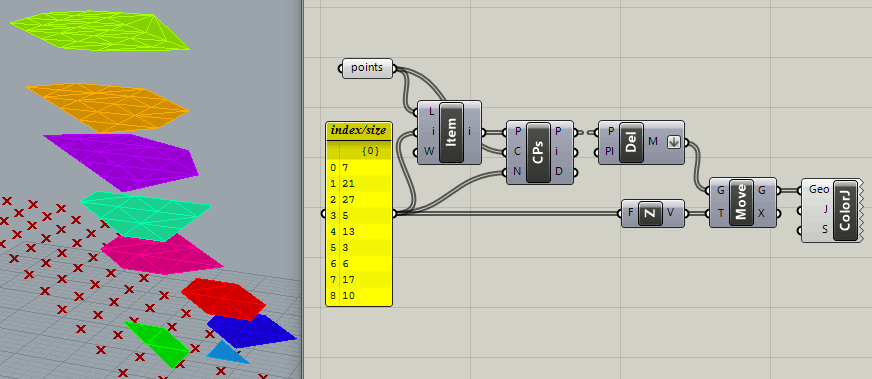
Looks like an answer to me! Joseph shows how you can create point cluster of desired sizes by grouping/clustering closest points together. This should also work for bigger point collections.
Yeah but it creates death corners in some situations.
Maybe I have to do it in Python but maybe it can be faster done with just the regular components.
I was also thinking of closest points but it sometimes create death corners.
By “death corners”, do you mean blind spots (German: “toter Winkel”)? Could you show and example of this?

Okay, there are no blind spots anymore.
But, I get those weird strokes, like that yellow stroke as in the image.
Hmmm… do you might know how to avoid that. I am trying to make it as clusters instead of strokes.?
@Joseph_Oster @diff-arch @Dancergraham
problem_sortClusters_01.gh (27.2 KB)
@ForestOwl, could you post a concrete example of what you mean by “cluster”?
Also there’s a RGB (Colour RGB) component that works basically like Pt (Construct Point). You thus don’t need to format the colour with an expression.
The points “more compact together” to form a function area of a building.
I cannot think of something to make the group of points more compact.
What is your native language? Maybe Google Translate can help us understand what you are trying to do: https://translate.google.com/
Any why Python?
So you wish to move some of the points, not just select groups?
Do you want to compact the points together, which would mean that the distances between clustered points would change/shrink, or do you want to cluster the points in such a way that useful ground plans would emerge, like shown in your diagrams? For the latter, would you be gunning for square, rectangular, or polygonal groupings, basically straight walls?
My guess would be that either way, you’ll have to introduce clearer parameters!!
For instance, the diagrams above show where exterior circulation meets/enters into the building. These points could be where the “clustering” starts. The same role could be played by the interior circulation.
Another parameter could be your spacial program. What kind of spaces or rooms (e.g. café, bicycle storage, etc.) do you want to distribute/generate? How big does each space at least need to be in terms of its area? These areas could define how big a cluster gets.
With these simple parameters or even more, it’s surely going to be easier to come up with a strategy! But is this what you want?
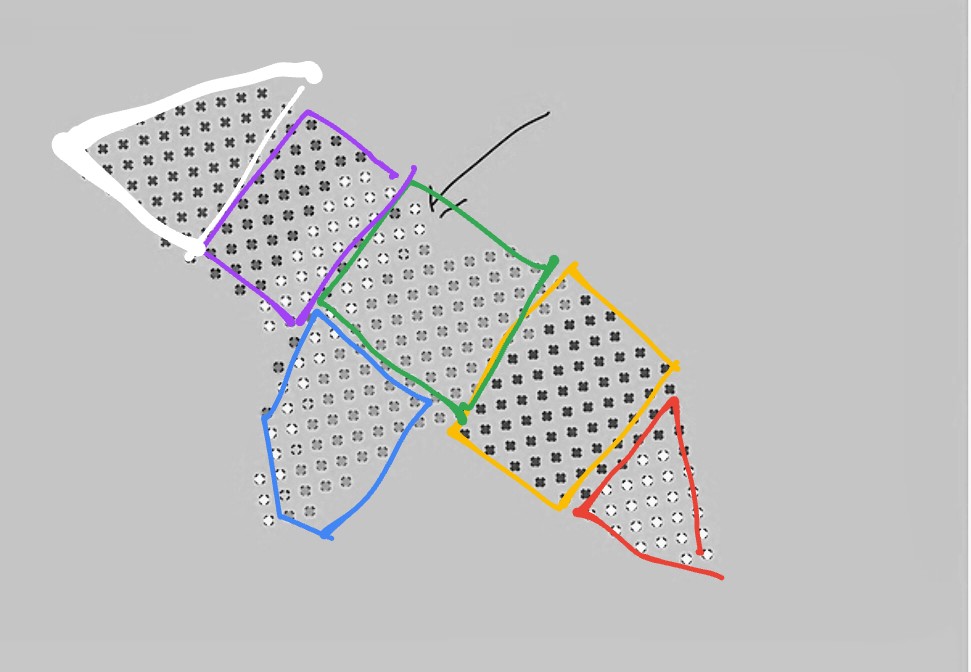
Like this. And it has not to be blocks of rectangles, circles, or triangles. What I am trying to prevent is functions which forms towards strokes. The yellow stroke is very stretched out which makes the space very difficult to design with interior.
I have the sizes of the spaces and translated that to the amount of points. @diff-arch
But now it is about having a good strategy for the formation of the spaces: the forms of the spaces connected to the size of the spaces formed not as strokes but as more useable stretched area.
That is my problem and am not able to solve it.
Parameters for example. External, internal circulation, but then it circulates?
I was thinking of more something like oil stains. But maybe that is impossible.
If I understand you correctly, you don’t want too narrow, long point clusters with small-ish areas?
After the clusters evaluation, which seems to work already (?), you could re-evaluate the clusters, identifying the unwanted ones, and for instance equally redistribute their points among neighbouring clusters.
You could identify the long, narrow clusters by getting the bounding boxes of the clusters. Clusters with a long bounding box diagonal and a short bounding box x- or y-size should give you the narrow, long ones.
Neighbouring clusters could probably be found by searching for closest point clouds.
Or maybe refine the clustering in the first place.
So where do the equally spaced points come from? A mesh?
If I understand you correctly, you don’t want too narrow, long point clusters with small-ish areas?
More rectangular.
Or maybe refine the clustering in the first place.
Yes but I do not know how.
So where do the equally spaced points come from? A mesh?
Generated with python.
It al starts by taking a point on the edge of the field. Then it sorts the fieldPnts by distance to the startPn; after that it selects the fieldPnts based on the needed amount for the funcion’s space; and repeats itself like this.
But, how to direct the form stays difficult for me.
I do not know about the right strategy to solve it.
@Joseph_Oster @diff-arch @Dancergraham
Space Syntax does not work here, I think.
So, to be clear, I want the function forms more concentrated to a center of the function itself.
However, as you can see I am not able to direct the functions to a more ‘circular form’ or ‘more rectangular form.’
What could be a strategy for that?
1.It takes a point of the edge, the startPn.
1.It takes the points closest to the startPn.
2.Search for a nextPn.
3.Repeats itself.
Problem, it let create point cluster structures which are formed as a stroke and is by that not useable as a space.
I am trying to find a way wherein the spaces are more ‘circular’ and less like a ‘stroke.’ The problem is, when doing so, there might will come blind spots.
Sounds like a good job for a trained neural network : the human brain is very good at this type of task Could you script it such that you can click on any area you want to ‘explode’ and it will go back and redo the loop from that point so if you click on the 8th colour in your loop it will explode from 8 onwards, try the 9th at that point instead and continue looping to the end, putting colour 8 back in at the end of the list…?
Also if the aligned bounding box of your points is very sparsely populated or very elongated then you could explode it automatically…?