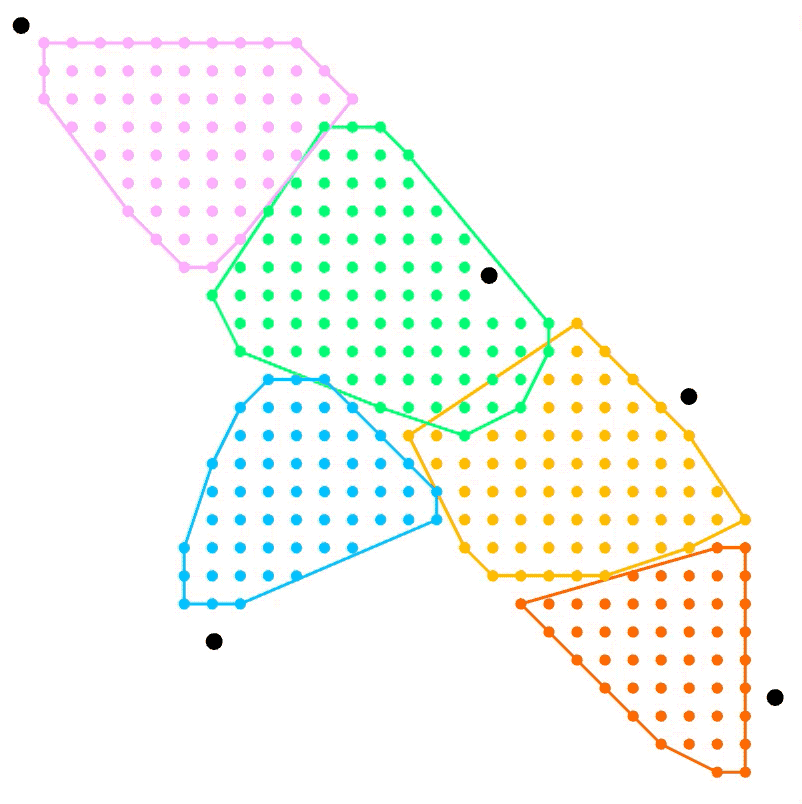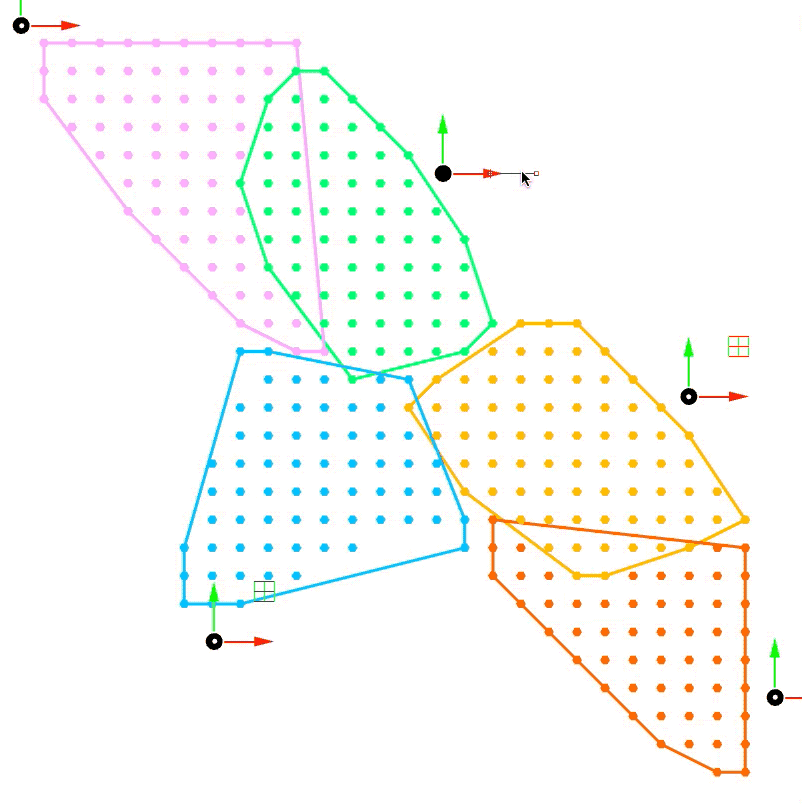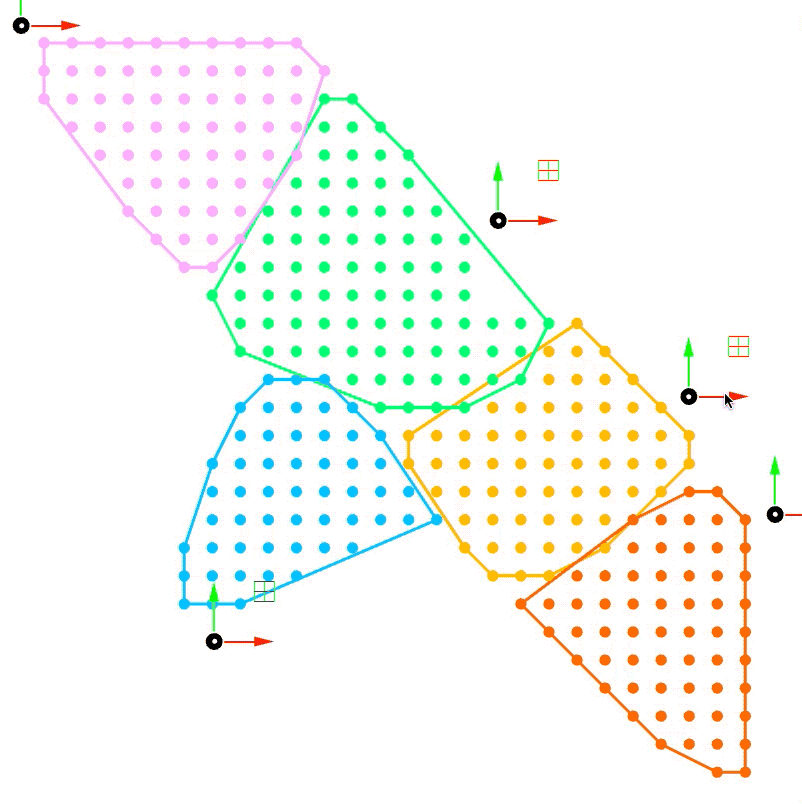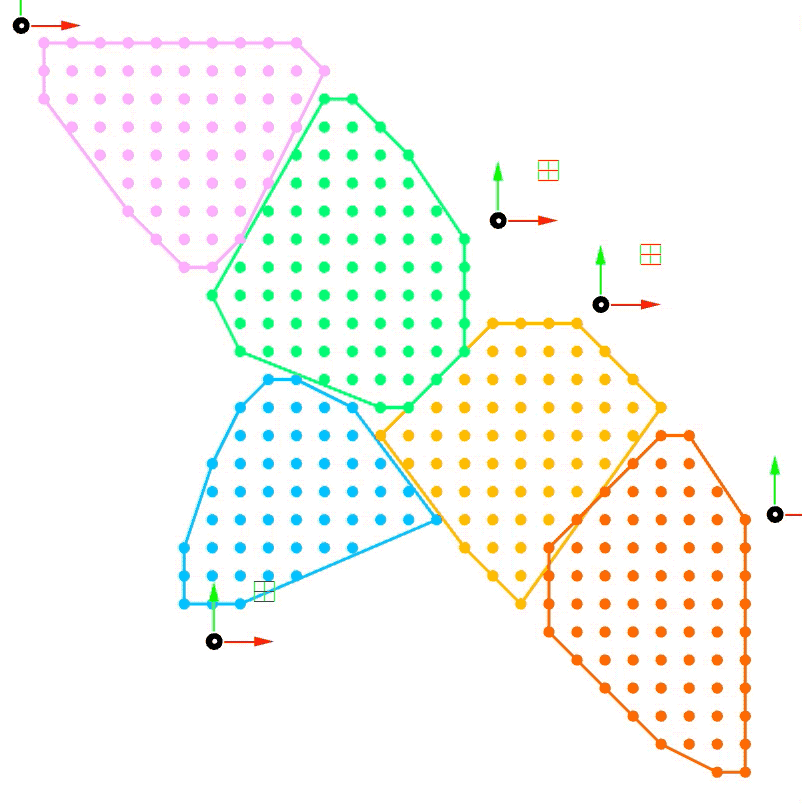
I’ve experimented a little and managed to come up with a similar result than your above sketch.
Each cluster begins at a start point (closest point to each black point) and has a certain desired size. At each iteration the search radius is expanded by a step size and thus new closest points are found that are then added to the clusters. If a cluster has reached a desired size, or doesn’t find any new, closest points within a threshold, it stops expanding.

This has the unfortunate byproduct that some points (grey) don’t get allotted to a cluster, because all neighbouring clusters have reached their maximum size.
However, the script allows you to add these points to their closest, neighbouring cluster, if desired! This obviously changes the cluster size, surpassing the desired maximum size from before for the concerned clusters, so it’s optional.


import Rhino.Geometry as rg
from ghpythonlib import treehelpers
# Get the diagonal length of the points' bounding box
bbox = rg.BoundingBox(Points)
bbox_dlen = bbox.Diagonal.Length
# Get the start points from the points
start_pts = [Points[i] for i in StartIndices]
# Temporary point cloud keep track of unchecked points
temp_ptcloud = rg.PointCloud(Points)
# Temporary indices keep track of unchecked points inital indices
temp_indices = [i for i in range(len(Points))]
curr_step = StepSize # current step size
count = 0 # iteration counter
# Intialise an empty cluster list for each start point
clusters = [[] for _ in start_pts]
active = [True for _ in start_pts]
while temp_ptcloud.Count > 0 and curr_step < bbox_dlen:
for i in xrange(len(start_pts)):
# Skip inactive clusters
if not active[i]:
continue
# Get the current closest point indices
rc = rg.RTree.PointCloudClosestPoints(temp_ptcloud,
[start_pts[i]],
curr_step)
closest = list(list(rc)[0])
if len(closest) < 1: # no current, closest points
continue
# Get current cluster points (if it isn't empty)
curr_cl_pts = None
if len(clusters[i]) > 0:
curr_cl_pts = [Points[k] for k in clusters[i]]
misses = 0 # counts closest points beyond threshold
for j in xrange(len(closest)):
# Skip index out of range errors
if closest[j] >= len(temp_indices):
continue
# Skip clusters that have reached the desired size
if len(clusters[i]) == ClusterSizes[i]:
active[i] = False
continue
# Get the current, closest point
closest_pt = Points[temp_indices[closest[j]]]
# Check whether the closest point is near the cluster points
if curr_cl_pts != None:
dists = [pt.DistanceTo(closest_pt) for pt in curr_cl_pts]
if min(dists) > Threshold + Threshold * 0.05: # 5% leeway
misses += 1
continue
# Save the closest indices to the current cluster
clusters[i].append(temp_indices[closest[j]])
# Delete the visited points and indices
temp_ptcloud.RemoveAt(closest[j])
temp_indices.pop(closest[j])
# Deactive the current cluster if no valid closest point were found
if misses == len(closest):
active[i] = False
# Grow the search radius and iteration count
curr_step += StepSize
count += 1
# Check whether all points are included in one of the cluster
if AllotRest and sum([len(c) for c in clusters]) < len(Points):
# Loop the remaining point indices in reverse
for i in xrange(len(temp_indices)-1, -1, -1):
rest_pt = Points[temp_indices[i]]
# # Identify the closest cluster
min_dist = float("inf")
closest = None
for j in xrange(len(clusters)):
cl_pts = [Points[k] for k in clusters[j]]
dist = min([pt.DistanceTo(rest_pt) for pt in cl_pts])
if dist < min_dist:
min_dist = dist
closest = j
if closest != None:
# Add the remaining point index to the closest cluster
clusters[closest].append(temp_indices[i])
# And remove it
del temp_indices[i]
# Outputs
Clustered = treehelpers.list_to_tree(clusters)
Unallotted = temp_indices
problem_sortClusters_02.gh (18.9 KB)