I’m trying to design the following type of facade where the inner offset triangle is based on the movement of one point along a vector changing through attractor point data.
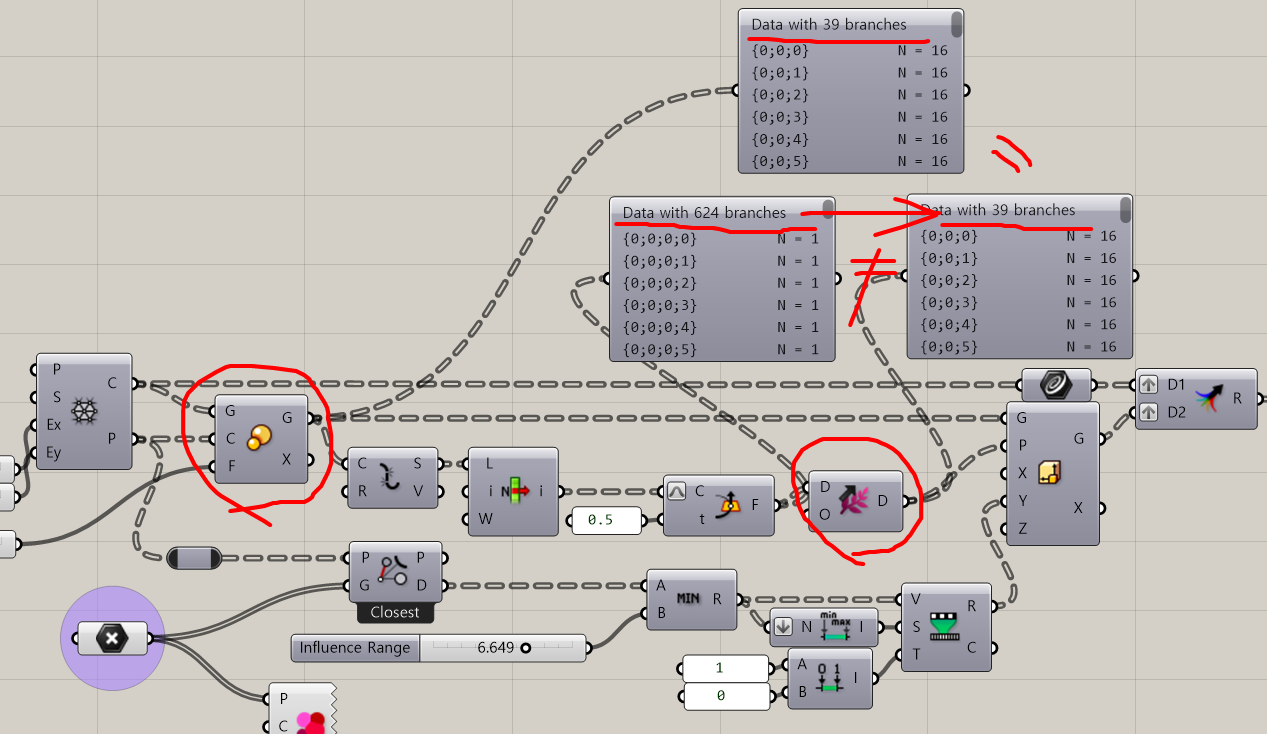
Thanks a lot again. I’m still trying to figure out the usage of various components here. The most complex computation it seems like is done by shift path. What exactly is it doing here?
If you compare the data tree structure before and after Shift Paths, it brings the modified data tree structure due to Explode back to the orginal data tree from Scale.
In your script, you didn’t flatten the output of triangular cells and the script is functioning totally fine. How is data matching happening? I am not able to understand.
How did you arrive at 6.649? While playing with the slider, I realized that after the value of 10.000, nothing happens. Please provide your method of calculating for this number.
Okay. Yes. You’re right, when the output of cells aren’t flattened and I flatten my bounds input, the script works fine. All this time I thought closest point component requires uniform flattened data in a single branch in such cases so it is doing a comparison for all the distances from the triangles in one single branch.
I also had thought earlier that if we don’t flatten the output of cells, the comparison happens branch wise. I.e. in every branch there are equal number of triangles, i.e. 20, so only one triangle per branch will get selected for closest point calculation.
What exactly is happening now when branched data is inserted into closest point component?
That’s a misunderstanding. If you have a look into the Cloest Point’s CP index output, it will spit out the index number of your closest attractor point(If your point attractor count is 3, that will be one of 0~2) per point in your grid branch.