Why does the tree with only 1 level of indexing get shifted into non-existence?
Wouldn’t it be better if in cases where the shift offset is bigger than the tree depth just have the output as a flattened list?

2 Likes
Yes. Definitely. For sure. OBVIOUSLY.
2 Likes
I normally go around it with checking the tree depth and making two parallel flows (flatten/shift) but it’s really annoying 
2 Likes
This is INSANELY annoying! This is a flaw that should be fixed, and I don’t care who’s code the fix might break. It’s a mistake to work as it does.
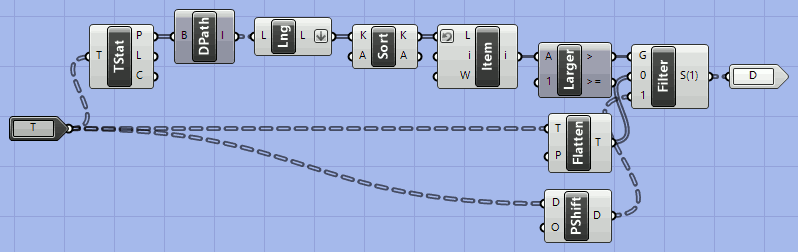
I just created a “Smart PShift” cluster to handle this. pShift works for me, though perhaps could be done better?
It is demonstrated in the following code, internal to another cluster crvXYZ that sorts curves by X, Y or Z of their midpoints.

PShift_smart_2020Apr28a.gh (42.2 KB)
2 Likes
Yes, I also find this problem and think the shift paths component really needs to be optimized.
I forgot to include the ‘O’ (Offset) input for my “smart” pShift cluster… but I never use it and the code would have to avoid the same problem of “shifted into non-existence” by the offset value.
Yes, currently facing the same issue. Most of the times I didn’t because my data structure was always the same in terms of depth. Now I am doing some “user interface like defs” and the multiple options change the depth of the tree. The reason the whole def was failing when options were changed was that the multiple ShiftPaths components were returning null data. Really annoying. Thank you @Joseph_Oster for the workaround.


Hi, I have created a video tutorial where I explained why to avoid simplifying data trees. You can check the video here: https://youtu.be/-DNYJAcoD5E