Hi @MateuszZwierzycki and all,
thanks for releasing Owl.
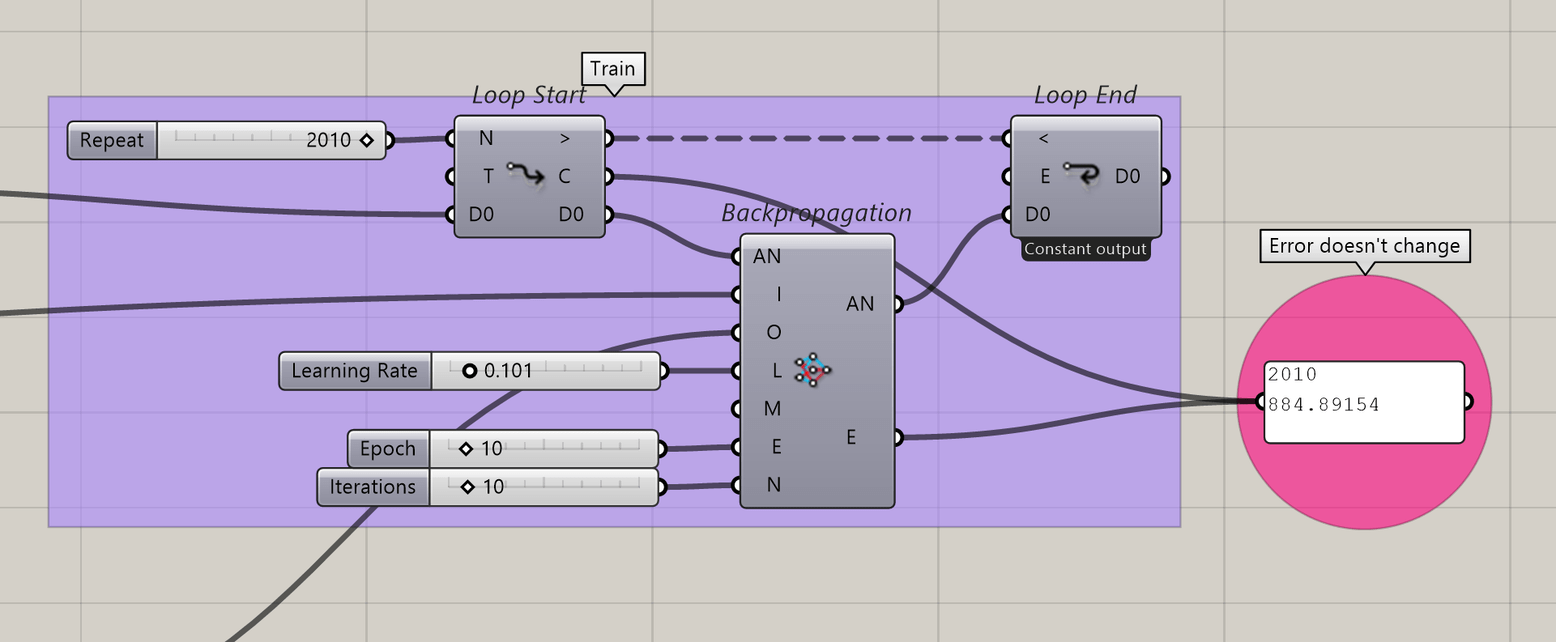
This is my first test. I’m making an auto-encoder using one hot tensors, but instead of having the same input and output, each output is interpolated with neighboring tensors (the topology is defined by an index datatree). However, the error is not minimized, nor changed at all, using backpropagation, what am I doing wrong?
AutoencoderOwl.gh (72.9 KB)
By the way, are you going to continue with the development? If so, what can we expect for the next version? I have missed the softmax function and more activation functions for the [Construct network] such as the linear one.
Thanks again and I wish you a great year!
@MateuszZwierzycki maybe you missed it?
You need to train the network a lot more. With 5 iterations for each loop, you probably want to have the Anemone run for 100s - 1000s times.
Thanks for the reply, but it doesn’t change a single digit in 2010 x 10 iterations. No idea what the problem is.
Hi! I could be wrong, but usually one hot tensors are good for classification problems - essentially having a 1 for the class the input belongs to. There was an example with it somewhere on the forum with digit recognition - your input is a 28x28 image - 784 dimensional tensor and the output is a 10 dimensional 1-hot-tensor, corresponding to the numbers from 0-9. In your case, your network is struggling to learn the function between the input and the output, since the input is a tensor with a 1 and 444 zeros. It might work but you will probably need a lot of data and probably grasshopper won’t be able to compute it in a reasonable time. In the example i mentioned earlier, the network was 784-128-10 and took around 15k samples and around 15mins to train. Try to rethink the one-hot-tensor. I think this is the choking part. Good luck!
Thanks for the help. If the problem was the convergence or the stability of the learning, what you say would be right, but if it does not change any of the first 5 decimals (I have also tried with other random inputs and outputs instead of OneHot), to me it seems more a problem of the hyperparameters, or of the component or of the algorithm, not of the use, since the network does not change at all. I don’t know, but I’ve tried other tensors.
EDIT: Of course, I might be using it incorrectly, but I don’t know where I can be wrong.
Well, seems like with less neurons in the hidden layer (12 with an input and output of 444) and the sigmoid act func it works  Apparently I was making a bottleneck too wide.
Apparently I was making a bottleneck too wide.
Edit: Applying the softmax function on the output tensor this converges relatively quickly.
1 Like