Lately I’ve been spending time debugging grasshopper scripts for use in Rhino.Compute and it has proved to be a bit of a bumpy ride. I’m creating this topic for general discussion on grasshopper best practices that make our Compute experience smoother. I’ve shared some of my experience below but am interested in what others have to say. If you have any gems for clearer error reporting, or pre-empting 5xx server codes, this would be a great place to share!
Environment Setup
Run in Compute Debug Mode
Debug Mode (setup via system variable) lets you copy the component ID of problem nodes and then identify them in a copy of the GH script when open in a normal non-compute instance of rhino.
Work Locally
The smoothest debugging experience so far has been working with a local compute instance, this saves the upload / download of scripts to a server, and removes any hassle from using remote desktop. It’s important for your local plugins ect to match your production server.
Save Requests and Responses
It has been very helpful to save a local json file with any requests made to compute and the response from compute. Using VS Code to review beautified requests for problems or compare two rx/rs to one another is very useful.
Script Setup
Have a system to import a compute request into your grasshopper script. This helps you to see if the issue was with the script or the script inputs. Often scripts will run fine when open in a normal instance of grasshopper, and then you know your issue is around a compute specific constraint like referencing the rhino document, or a missing plugin.
Add descriptive custom names to parameters. The terminal will tell you the name of your error components so adding custom names can have benefits but also drawbacks. If you name multiple parameters the same thing, then it wont help you know which one is the problem without searching for its GUID. I used to think any custom names should be applied to a group around a parameter, because changing the name can confuse a parameter’s true type, but now I’m not so sure. Maybe the answer is to only add custom names to panels and have panels for all key outputs.
Avoid clusters. Debugging mode will only tell you that the cluster had a error but not which node inside the cluster. I think avoiding clusters is good practice regardless, but many production scripts deploy clusters for ease of use by non-power users, so it is a common reality.
Use metahopper to identify all assemblies that the script uses so its easy to quickly check if you might be missing one of them on you compute system.
Try and avoid stream filter. I’m not 100% on this one, but have seen errors with their use that appeared to resolve once the filters were removed. Any one else seen this?
I have been thinking about creating nodes that could report custom messages like “this part of the script passed” and then feed all messages out as a list, but haven’t tried this idea yet.
Hard Rules
Never reference the rhino document - it doesn’t exist in compute
@Nicolas_Azel I think these are are very good points. I’d like to add a little more clarity on a few of your ideas.
Saving Request and Responses
First, in the environment setup you suggest saving request and responses. This is a great idea, although a little tricky if you aren’t fairly well versed in running compute in debug mode, etc. I’ve added a new feature which will be available in the next release which lets you export each API request/response made from the Hops component (as a JSON file).
For example, Hops initially sends a request to the “IO” endpoint where it uploads a serialized version of the referenced definitions to the rhino.compute server. The compute server processes the request and returns a response which contains the necessary information to setup the inputs and outputs for the Hops component itself. Once the Hops component is “built” with the necessary inputs and outputs, it gets the incoming data and now sends another response to the “Solve” endpoint (with a reference pointer to the definition that the server should use as the base definition). This “Solve” request contains the input data defined by the Hops component. The server then processes the definition using those inputs and returns the result (the output) in the response message. The Hops component receives that response and delivers the data to the correct output parameter. So, with this feature, you should be able to inspect each API request and response being made - hopefully helping you troubleshoot your errors if you have any.
Break up your definition into functions
I think another good tip would be to analyze your definitions and try to break up long definitions into smaller “chunks” which can be saved out as separate definitions and referenced into a “main” definition using Hops. There are several reasons why this is useful. First, legibility. By breaking up a very long definition into smaller sections (let’s call them functions), you can clean up the spaghetti code which often makes big definitions inscrutable. Secondly, depending on how you setup your server environment and the “main” definition, you can get performance gains by sending different Hops definitions to different child processes. Third, by breaking a definition down into smaller parts, you have the ability to reuse those saved functions in other definitions if needed. Lastly, getting into the habit of breaking your definition down into “functions” is very good practice. It’s essentially what “programmers” do when they analyze their code and abstract areas down into functions. Functions allow you to break a program down into more manageable pieces; making it simpler to manage, easier to test, and apt for reuse.
RH_IN and RH_OUT should be on primitives (number, boolean, etc) not GH components such as ‘Panel’ (even though it holds a string or number)
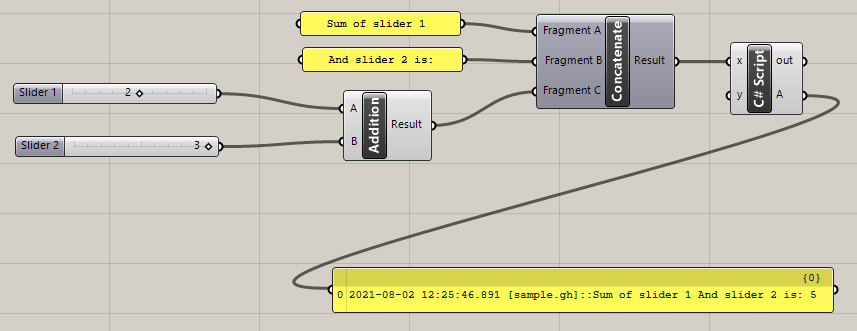
Console debugging.
We use the following snippet in a C# script component to be able to output arbitrary logging text when debugging on a remote server.
Rhino Document
You can create a fresh ‘Headless Doc’ using a C#/Python script component (RhinoDoc.CreateHeadless Method), however you should only have one script component that creates a headless doc. (We do this for import 3dm’s in, and also exporting 3dm/dwg’s
Hi @b0g3. How you save a request can very depending on how your sending them. Andy Payne notes how you can do it via hops. Once you have a .json request file you can read it into grasshopper and pull out your values. For any geometry in the request you can convert it to a rhino common object with CommonObject.FromJSON Method (String).
Hi Nicolas,
Thank you for the great tips! very helpful.
I’m trying to run a grasshopper script through rhino.compute, and the script uses a plugin, which I think requires referencing the rhino document. (open nest)
for example:
tolerance = scriptcontext.doc.ModelAbsoluteTolerance !
Is there any way to input a sample rhino doc parameters as variables to the rhino.compute solver?
@coroush The ModelAbsoluteTolerance and ModelAngleTolerance is already included as part of the Hops request. This was added a few releases ago. If you right-click on any Hops component (assuming you’ve already set the path and run it at least once), then you can export the last IO and Solve request and response. For example, I just ran a very simple Hello World example and then exported the request and responses from the IO and Solve endpoints. The IO request looks like this:
Note: I’ve just added the tag modelunits to the HTTP request so now you can see what the current model units are in your Rhino file. But, this wont be available until the next Hops release.
Using @steven.downing’s great logging tip I was able to see that my SolidUnion component fails to produce a brep when my TestWithLogging.gh (24.9 KB)
script runs on Compute environment but yet it worked just fine on the desktop.
Thinking about this made me realize it was a tolerance issue and so I added the absolute tolerance, angle tolerance and units parameters to my outbound calls thanks to @AndyPayne’s example above.
This solved the issue and now my scripts are running as expected on Compute.
Thanks you both for your great posts!