Hi all,
I was hoping to get some ideas on how other users handle and pass big data-structures.
What i wanted to ask, is anyone aware of any GET/SET type methodologies where we can push data into a titled datatable, then fish them back based on title to clean up messy scripts and create a nice clean workflow?
I saw some data-tables and datasets as part of the Lunchbox Plugin, but couldn’t figure out how to actually use them in the GH canvas.
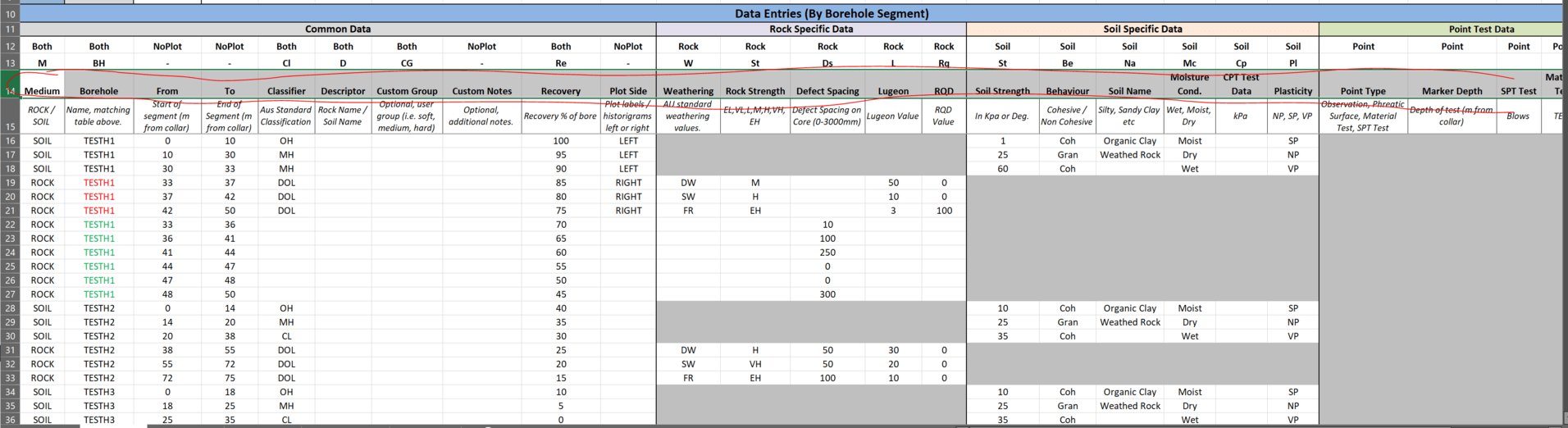
I’m working on a fairly complex (for me at least) geotechnical modelling script to present underground data parametrically. Like all good projects mine has been going about 10 years, and had substantial scope creep (You can see Rev 1,2,3,4 in sequence below):

To tidy things up i wrote a basic data-table type function (Which i called GET/SET in line with programming nomenclature).
Getting me here:

Each package in the linear chain effectively looks up the info it needs, calculates the extra parameter, then pushes it back into the dataset.

I have attached a basic script which demonstrates where I have been going with this. Presume this has probably be done before (or that it hasn’t for good reason!) - so any thoughts would be appreciated.
Demonstration of Get-SET (GH Lookup).gh (21.6 KB)
Note: The attached script is OBJECT BASED (I.e. each branch of the tree has pieces of different meta-data associated with one object, or data segment). I also have a parameter based lookup which goes the other way, with each list containing a single data type, but applicable to multiple objects. This deals better with lists which are not of uniform length, but i am more concerned about data corruption if i accidentally delete a list item and the data becomes misaligned.
Thanks in advance!
LJ








 I’m based in Tassie, I have looked at geometrygym previously and it looks really interesting. I’ll do some reading first, if you have some stuff on your website I can trawl?
I’m based in Tassie, I have looked at geometrygym previously and it looks really interesting. I’ll do some reading first, if you have some stuff on your website I can trawl?