Dear experts,
I´m trying to cluster some relatively complex data tree using Lunchbox´s K-Means component
KMeansAnemone.gh (28.0 KB). However, it complains with the following error when I directly input such data tree:
1. Solution exception:The points matrix should be rectangular. The vector at position {} has a different length than previous ones. Parameter name: x
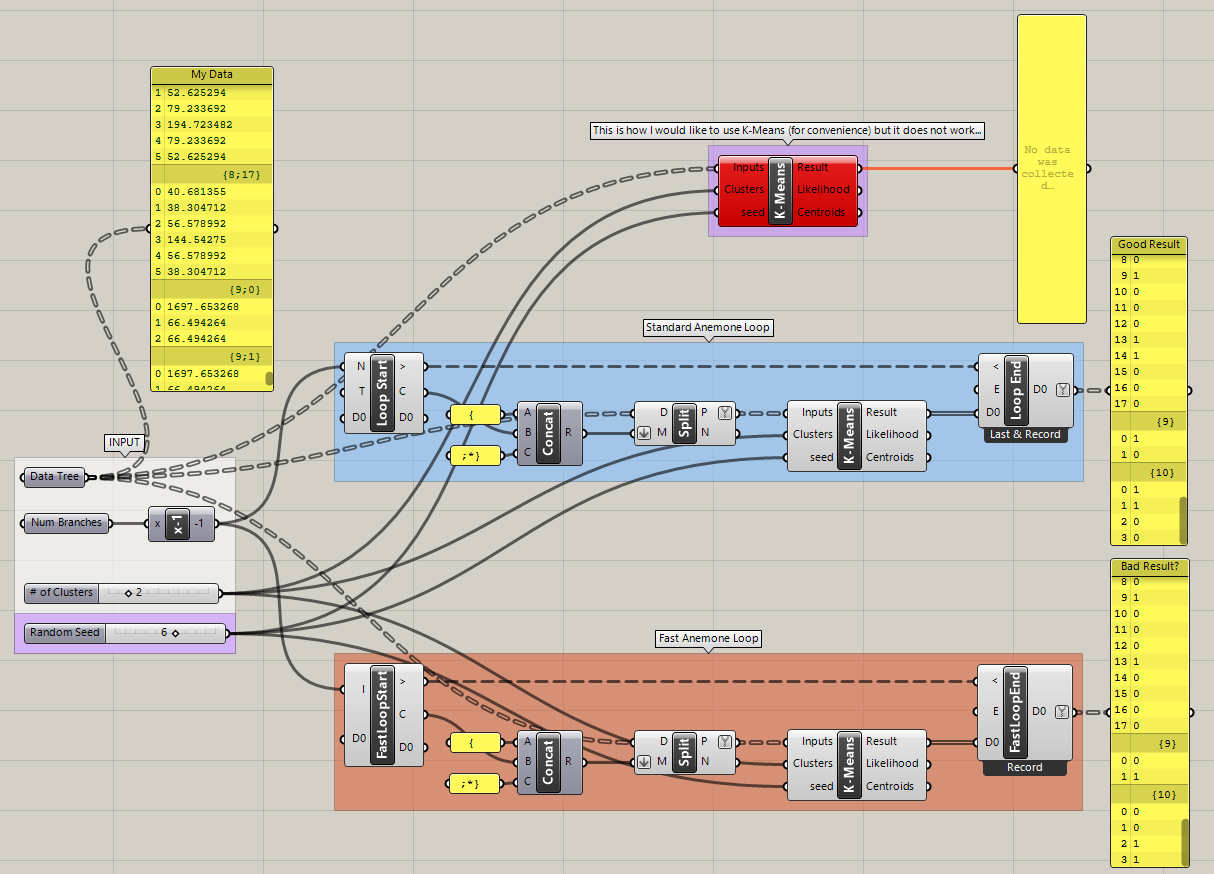
Since my data tree may have different number of branches and elements depending on the case, I decided to use a simple Anemone loop to obtain the desired “Good Result”.
Three questions:
-
Is there any way to directly run K-Means with my complex data tree? Perhaps calling K-Means using some fancy C# code?
-
When the Anemone loop is integrated into a much bigger GH sketch to perform some Galapagos or TT Toolbox´s brute force optimisation it systematically fails most of the iterations.
-
Whereas the results from the “Standard Anemone Loop” (blue group) are always the same for different seeds, the results from the “Fast Anemone Loop” (red group) always differ unless a Random Seed of 9 is used instead.
Any help is welcome! Thanks!!
