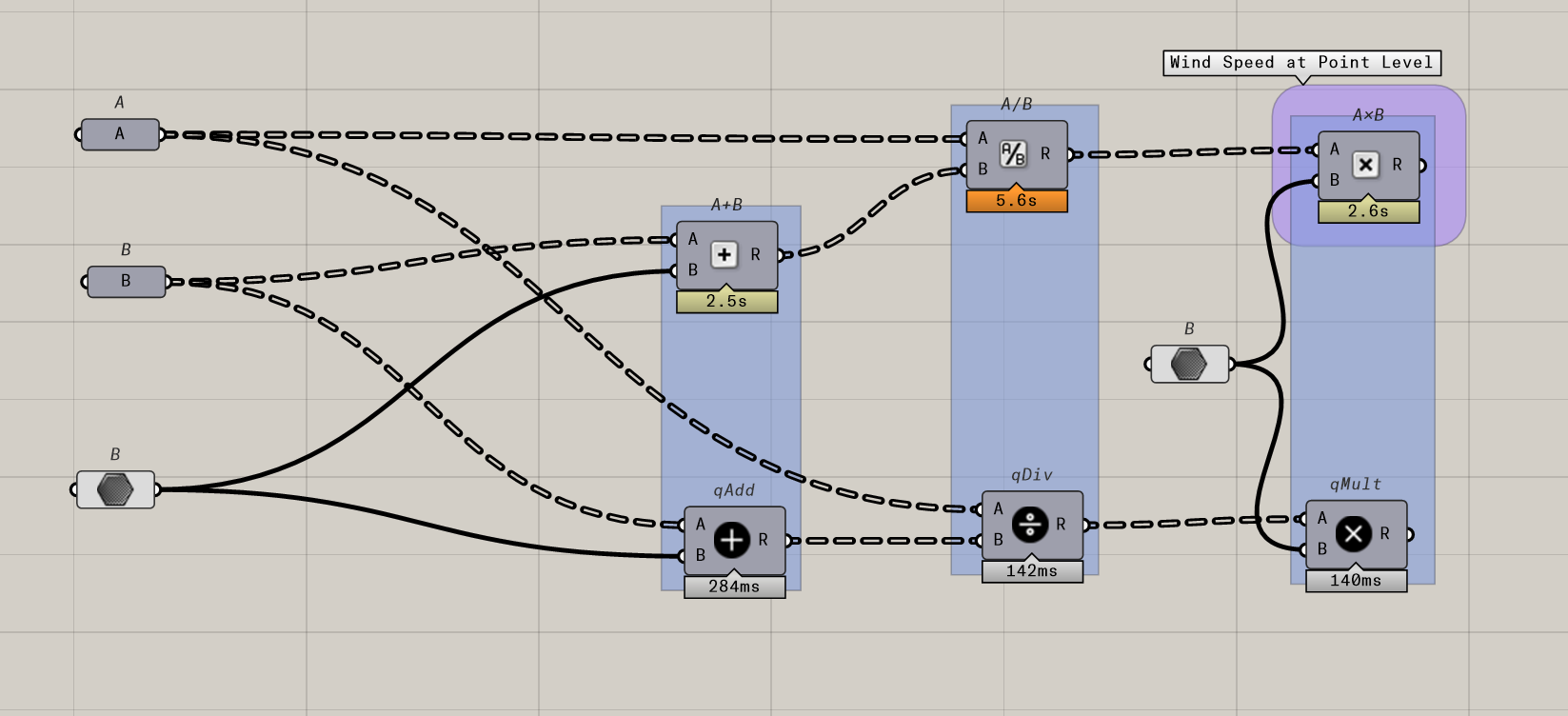
I am trying to perform simple arithmetic operations on two very large data trees of equal size (~140 million values each). The process is extremely long (I waited for up to 4 hours) and takes up all my memory (I only have 16 Go).
For demonstration purposes, the two data trees in the attached Grasshopper file are much smaller (~2 million values) but still take several seconds to complete.
How can I speed up the process of working with very large data trees and use less memory?
I guess the best would be to do as many calculations as you can outside of Grasshopper, and only bring back the results… Extra step, but could maybe speed up (except writing to and reading from will probably quite heavy as well)
But may I ask how one could ever need that many values?
My guess from the screenshots - to do calculations involving ground level wind speeds, e.g. for pedestrian comfort calculations, involving the output from a CFD solver plugin such as Butterfly or Swift. The two trees might be different climate or building scenarios using the same mesh of points
I’m surely not the one to tell what you should do… But doing this for every hours seems a bit overkill, especially when LB is already a bit vague on some data (estimates based on years, different type of entities collecting the data, …)
You may gain an incredible amount of computation time while having similar results (within 1% or less probably), with a fraction of hours per day. (I’m not even running it for all the days in each months…)
Thanks @Konrad! I will try this out.
But my problem is really the amount of RAM that is being used (~60 GB when I run the full version of the script on a 128 GB RAM machine). Will Impala also reduce this memory usage?
I did test memory usage and it seems to be the same:
When processing so many values they have to be stored somewhere I guess. You could try to write them to disc and then process them sequentially but I wonder if the overhead is not causing more problems. One thing I noticed is that the GH canvas gets very unresponsive with so much data regardless how fast impala can chew through the calculations. So GH just might be the wrong tool for the job