Interesting thoughts everyone, thanks for sharing.
I agree the industry is full of nonsense around AI. Let’s clear it up by learning more precise terms and connecting them to real, useful applications. I think our industry can have a more informative discussion if we focus on what AI/Machine Learning(ML) tools do, rather than what they are. Rather than throw around broad terms like AI, we should discuss particular algorithms, or even better, what these algorithms do. Most of us probably don’t even know what to google to learn more. I’ll try to fill this post with terms I find google-useful, so please forgive my obnoxious use of fancy words.
The way I see it, we have a variety of algorithms at our disposal (Genetic Algorithms, Neural Networks, Decision Trees, K-Means Clustering, etc.) that do a variety of things (Optimizers, Regressors, Classifiers, etc.). What we want to do determines which tool/algorithm to apply.
Optimizers:
I’m a skeptic. I worry that it’s too easy to unknowingly build assumptions into the fitness functions that optimizers rely on to generate the “best” design(s), making the results not actually optimal at all. Also, optimizers take the designer out of the loop. I don’t think design involves optimizing at all, as it can be so subjective. Rather, let’s accept that we are usually exploring or refining, not optimizing. If so, I suggest we focus on Multi-Objective-Optimization (MOO) so that our results are a collection of “better” ideas given the assumptions not a false single “best.” In fact, I think our industry should focus more on Design Space Exploration (DSE) techniques that inform the designer rather than optimizers that replace the designer.
Regressors:
Regressors basically interpolate and they go hand in hand with DSE. If you iterate a parametric model to generate a design space, you can apply a Regressor (Neural Networks work well) on the collected data to train a surrogate model of the entire space (See Design Space Explorer, Crow, Owl plugins). This is useful to replace slow parametric simulations with real-time predictive engines, which can then be used to power other generative techniques. Once you have mapped the entire design space using a Regressor, you can explore it using optimizers to identify “best/better” options, run sensitivity analysis on each parameter (Multiple Linear Regression MLR) to guide criteria prioritization, understand covariance, etc. Dimensionality Reduction techniques like Principal Component Analysis (PCA) and Self Organizing Maps (SOMs) come into play here, as they help clarify complex data. I like DSE because it is all based on building a good underlying parametric model of the design challenge to generate the necessary data/design space. We don’t have to have or find the data, we generate it ourselves. Once you have modeled your challenge parametrically and translated that problem into a database we can apply all sorts of AI/ML tools to mine that data for insight and apply it in practice. How are others applying these techniques? Please share with the community so we can all upskill.
Am I correct in thinking that generative floorplans are fancy applications of regressor applications? They “learn” from past designs to choose a new design based on a complicated interpolation of the training data? Rather than expect our algorithms to deliver a completed floorplan we can also break the problem into parts. WeWork showed a great example where the tool predicted the expected number of workstations that could go into any shape. This seemed more useful than generating a final layout (it also did that) because the designer would likely want to tweak it anyway. I’ve heard of Reinforcement learning techniques like Generative Adversarial Networks (GANs), Deep Q Learning being used for these types of problems.
Classifiers:
I’ve struggled to find good applications for Classifiers, or clustering algorithms. If we had the data we could classify go/no go decisions, identify problems in on-site construction images, flag documentation issues, but these all seem to require data that is harder to gather. What have others found? Gaussian Mixture Modeling (GMM) seems promising because it returns the probability that an input belongs to a particular cluster, rather than an explicit prediction. This fuzziness seems applicable to our world. GMMs are used to separate noise from background, like separating multiple instruments out of a single audio file, or a moving object from a still background. Perhaps edge detection/ object detection could be useful?
Are there other major application groups I’m missing? What do others think about focusing the conversation on what the algorithm does rather than what the algorithm is called?
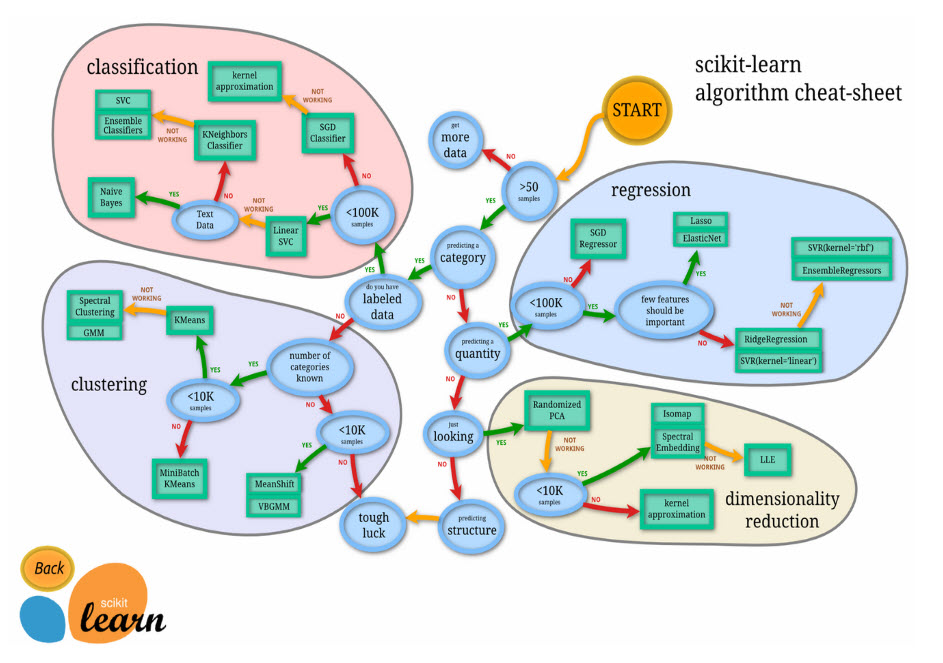
I like Scikit Learn’s cheat-sheet: