Hi all,
I am in doubt about transitioning from a development workflow with open-source code to a workflow with compiled components. How are others achieving this?
I lay out my precise question below under HERE is where I am currently stuck!, but I’ve shared how I’m currently developing and I’ve laid out two potential paths forward for context.
Option 1 will definitely work, but it is quite manual. I repeat the process for each of 20 components on a canvas, compile each one, and manually replace the ghpy files as needed.
Option 2 is less certain, but I think it can be automated. It requires significant changes to the source python code to ensure it can be compiled. I’ve hit some road-bumps with latin-1 encodings and batch-processing for multiple components.
Current Workflow:
-
The Grasshopper canvas has 20-ish Python components that point to .py files using the pattern in the image / minimal example below. (my previous post on setting this up)
-
The components run in the Procedural Script mode, not GH_Component SDK Mode.
-
Code is distributed directly using the same canvas.
-
Example of pattern & files (you will need to re-link Path 1 and Path 2 to Alex1stComponent.py and Alex2ndComponent.py, respectively in order for this to run):
CurrentDevelopmentAndDistribution_v0.0.gh (14.5 KB)
Alex2ndComponent.py (3.4 KB)
Alex1stComponent.py (3.4 KB) -
I prepare for distribution by tapping the ‘minus sign’ on the ‘code’ input parameter. That stores the last version of the Python code which was read inside the component, and breaks the connection with the .py files that I actively edit in Sublime Text.

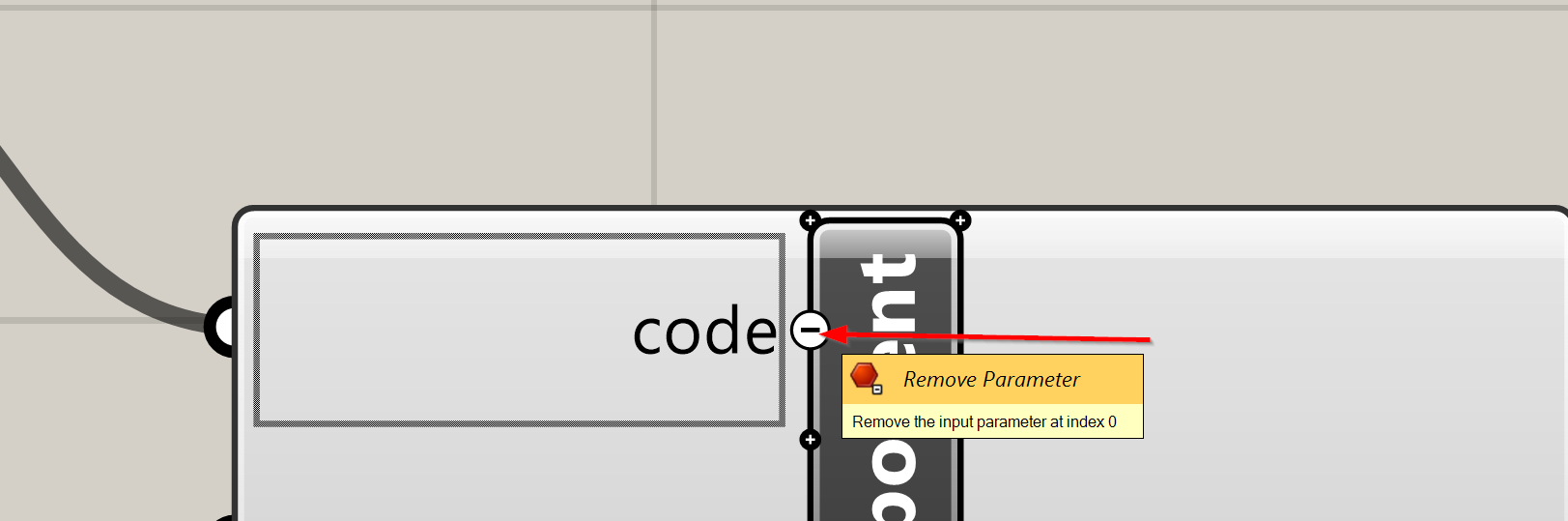
This process works great… but has these disadvantages:
- The source code is open
- 30-60 minute manual process of preparing a canvas for distribution.
Option 1 - Manual workflow
This is essentially following the steps in Giulio’s tutorial, adjusting ghenv to self, manually and then also manually adjusting the documentation strings too. This will be a pain in the butt to do for each individual component each time I distribute.
Option 2 - Automated workflow
-
The ‘development’ components always run in the GH_Component SDK Mode, so that I can run a batch-export process for the compiled components at any time.
-
I have two separate canvases, one for ‘development’ (above) and one for ‘distribution’.
-
The ‘development’ canvas continues to link to the source .py files directly. (Same pattern as above)
-
The ‘distribution’ canvas is built out of compiled components. Code in these components updates each time we update the GH Canvas. I only need to edit the ‘distribution’ canvas when I change the number of input or output wires on a component or add new components.
-
Here are example files:
Option2Development_v0.0.gh (13.1 KB)
Alex1stComponent_SDKMode_v0.0.py (4.3 KB)
Alex2ndComponent_SDKMode_v0.0.py (4.3 KB) -
I am trying to batch-process the export of these files using this canvas, drawing on code in Giulio’s example:
Here is the code for that:
Option2Development_ManualRemoveCodeAndOutParameters_v0.0.gh (40.5 KB)
Alex1stComponent_SDKMode_v0.0.py (4.3 KB)
Alex2ndComponent_SDKMode_v0.0.py (4.3 KB) -
@piac HERE is where I am currently stuck!.. When I use this code to disconnect all the relevant ‘code’ and ‘out’ input parameters. I receive an error related to the class no longer deriving from component.
if Toggle == True: for obj in ghenv.Component.OnPingDocument().Objects: if str(type(obj)) == "<type 'ZuiPythonComponent'>": if obj.NickName in NamesOfComponentsToPrep: if obj.Params.Input[0].Name == 'code': obj.Params.UnregisterInputParameter(obj.Params.Input[0],False) if obj.Params.Output[0].Name == 'out': obj.Params.UnregisterOutputParameter(obj.Params.Output[0],False)



Next Steps::
-
Assuming it is possible to automatically disconnect the ‘code’ and ‘out’ paramters, then I want to…
-
write out the strings that come from Giulio’s component to .py files
-
Compile those with another component that runs code similar to this (I have tested it already, and that works):
import clr outputPath = FolderPath + "AlexanderCompiledTool6.ghpy" inputPath = FolderPath + "Manual6_CompileTest1.py" clr.CompileModules(outputPath, inputPath)
(I’ll tackle the distribution in a separate post later… but the GHPY files will either 1. be distributed via an internal Yak server or 2. via Microsoft Sharepoint, whereby our IT department pushes Rhino settings that point Grasshopper to check the SharePoint folder for plugins)
Summary of manual edits to source code between ‘Procedural’ and ‘SDK’ modes:
-
ghenv.Component must change to self for the compiled code i.e.:
warning = gh.Kernel.GH_RuntimeMessageLevel.Warning message = 'Some warning message' ghenv.Component.AddRuntimeMessage (warning, message)needs to be this:
warning = gh.Kernel.GH_RuntimeMessageLevel.Warning message = 'Some warning message' self.AddRuntimeMessage (warning, message) -
All python files use Latin-1 characters, so this must be added to the top of each .py file
# coding=Latin-1 -
I have been using aliases for Grasshopper and Rhino common… so I am simply running the import twice. i.e. SDK mode requires these import statements:
from ghpythonlib.componentbase import executingcomponent as component import Grasshopper, GhPython import System import Rhino import rhinoscriptsyntax as rswhereas my current code uses these import statements:
import Grasshopper as gh import Rhino as rcwhich means that Grasshopper and Rhino are being imported twice…
Remaining gaps:
- I also had problems writing out the code that Giulio’s component outputs to .py files that can be compiled… something with encodings and interpretation of a unicode single quote character.