Hello,
I used Octopus just a couple times before but have never realized that.I just ran 2-criteria optimization with it and realized population size is doubled for each generation. I was sure it would happen for the first generation (as it does on default in Galapagos and most other 1-fitness solvers) and it did.
I do not understand why next generations are doubled as well (i used population of 30 and its 60 4th gen in a row).
If I understand it right, the manual states that this would happen with ‘fillrandom’ checked (so populations are doubled until 2x population size of valid solutions are found. The thing is, I do not have any constraints or penalty functions, so I belive this should be met in first generation.
Is it a bug or am I missing something important on the theoretical side?
@robert_vier I’d be grateful for your input.
Hey,
it is not a bug nor of any relation to ‘fill random’ (the latter is if you connect a boolean hard constraint as an objective).
The entire pool of a generation consists of the population size, plus the archive of same size.
The archive stores all the individuals which you do not want to loose.
The population size gives the number of individuals which are newly bred and evaluated in each generation (the ‘living’ generation).
I could as well make the pop-size define the size of the entire pool and divide the number in two, but the common way to do this in the literature I used for octopus is the way I did it.
Check my thesis which describes an early state of octopus but is the closest of a documentation so far.
https://www.researchgate.net/publication/283073414_Multi_Objective_Design_Interface
Cheers
R
Thank you very much,
Your thesis shed some light for me. I obviously didn’t read the full thing yet. It seems to be written in simple language and well-explained for people without scientific background like myself so I defienately will.
So, now I understand (more or less) why archive is needed for new generations. What bothers me is why are these re-calculated. I assumed they are since my definition uses data recorder and saves all solutions to excel. Out of ~230, ~80 genomes were duplicates.
Algorithm chooses best found solutions archive. As these genomes and their corresponding fitness were already found why these need to be re-calculated?
This is rather painful in time-consuming definitions (such as mine - one genome=80sec)
Once again, thank you for your time, help and that link!
Have a good one!
If an individual was evaluated once, it will not be re-evaluated. The archive will not be re-evaluated. Only the newly generated population will be re-evaluated.
Best
R
Now i know it has to be my mistake somewhere or the way other plugin components handle slider changes because some combinations are being evaluated more than once (according to data recorder). Anyway - I’ll just ignore it for now.
Once again, thank you for your clarifications, time and help.
Hi Robert,
I`ve been using OCTOPUS for a while, try to implement it into pratical architectural strategic decison making.
I got lots of questions, but will detailly go through your thesis first.
BUT, can you explain the “FILLRANDOM”?
So we can use true and false as an objective?
Thanks,
Lei
Hi Robert,
I have read your thesis and definitely push my understanding of MOEA into a deeper level.
However I see your paper used the old version of OCTOPUS and hence the instruction of it cannot
match the current version. cuz` you have lots of new function and development.
i.e. we can mark Pareto-front solutions with blue(preferred obj), and from the simulation it could tell the simulation direction or trend tends to be directed by these blue marks. So I guess now we can check the simulation time by time and subjectively lead the simulation direction?
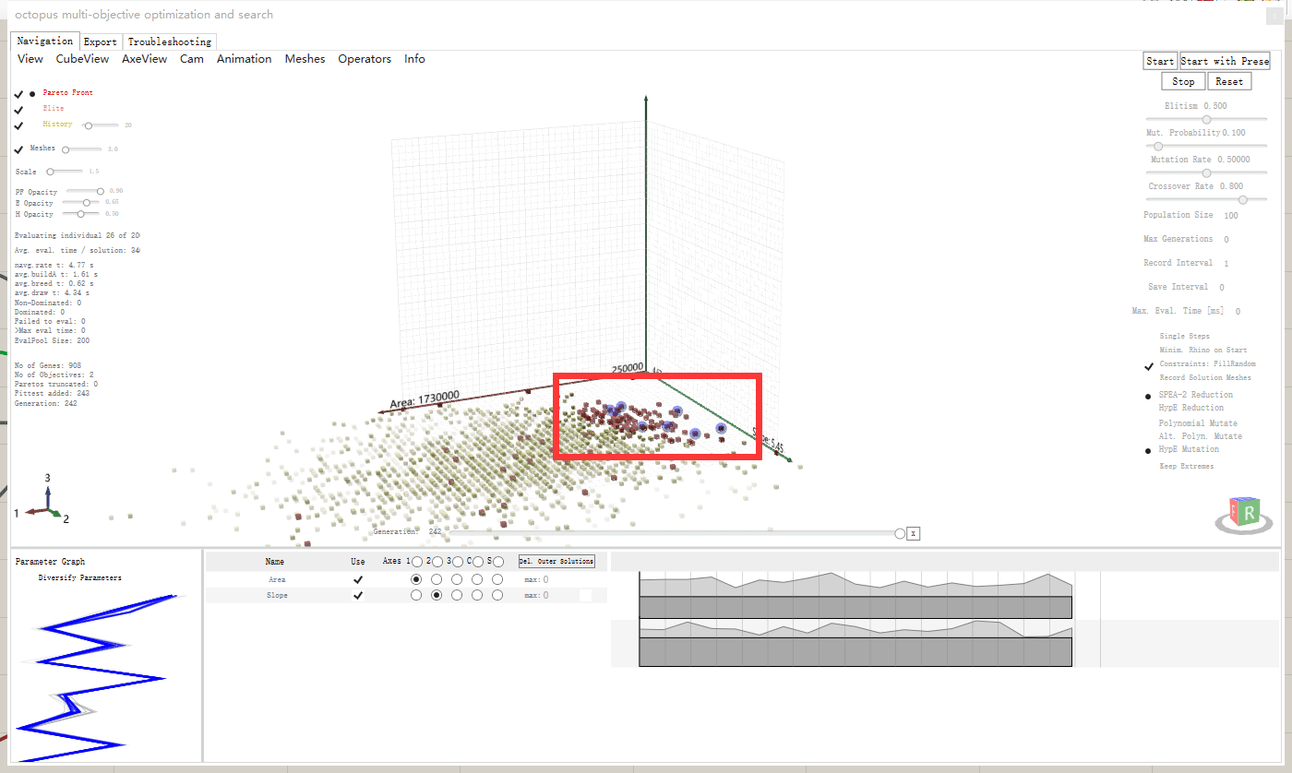
It will be really brilliant if you could post a new MANUAL of current OCTOPUS USER GUIDE.
And I was wondering if you could share your e-mail so I could send my practices back to you as some samples of GA?
Best wishes.
Lei