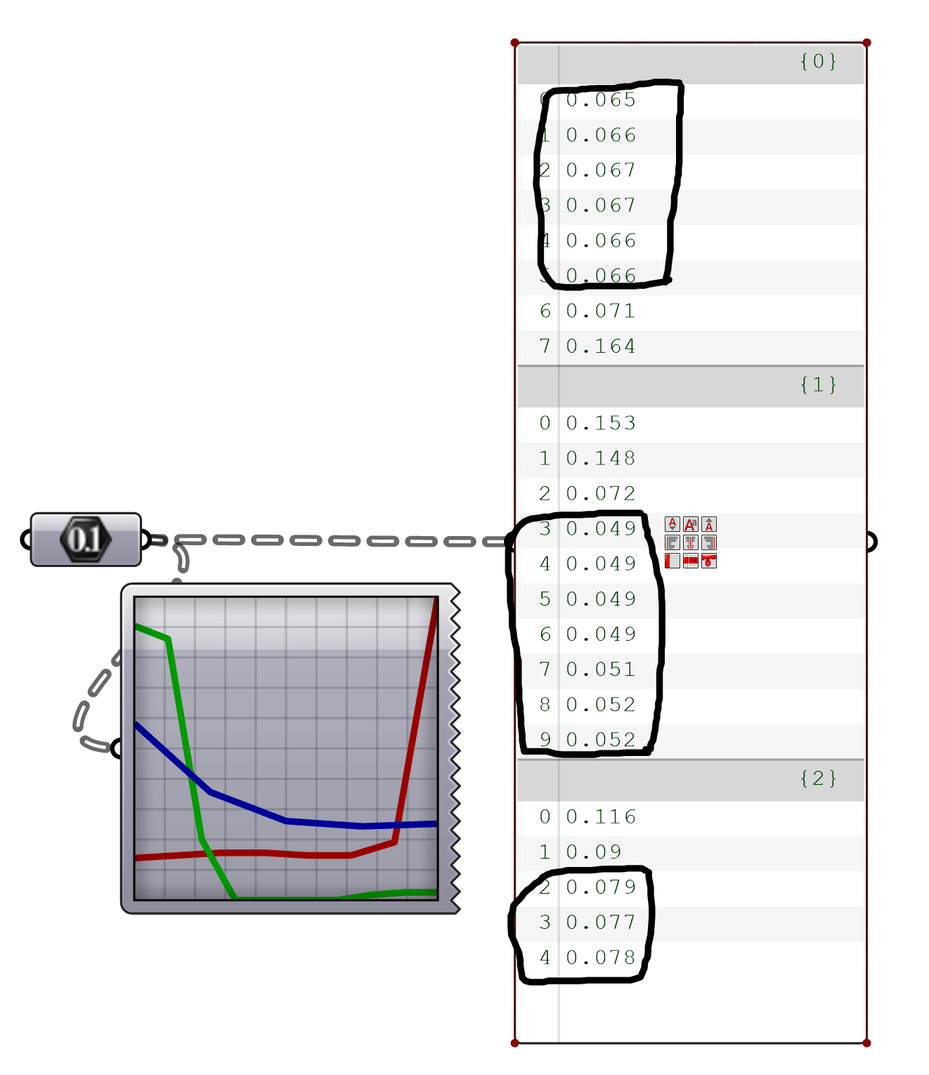
I am trying find a method how to extract a list of numbers from a list that are the most self-similar?
I would like to filter out values that stand out too much from a general list.
From screenshot attached first list would return
0.065, 0.066, 0.067, 0.067, 0.066, 0.066
second
0.049, 0.049, 0.049, 0.049.0.051,0.052
One idea was to use K-Means clustering for the list.
But I am wondering if there is a simple mathematical way to get this?
I do not mind using .net math numeric libraries if needed.
using System.Linq;
private void RunScript(DataTree<double> data, double threshold, ref object A)
{
A = GroupSimilarNumbers(data, threshold);
}
// <Custom additional code>
public DataTree<double> GroupSimilarNumbers(DataTree<double> data, double threshold)
{
DataTree<double> Out = new DataTree<double>();
for (int i = 0; i < data.BranchCount; i++)
{
Dictionary<double, double> groups = new Dictionary<double, double>();
for (int j = 0; j < data.Branches[i].Count - 1; j++)
{
double val = data.Branches[i][j];
double nextVal = data.Branches[i][j + 1];
if(Similar(val, nextVal, threshold))
{
if(!groups.ContainsValue(val))
groups.Add(val, val);
}
if(groups.Count > 0)
{
foreach (KeyValuePair<double, double> entry in groups)
{
if(Similar(val, entry.Value, threshold))
{
if(!groups.ContainsValue(val))
{
groups.Add(val, val);
break;
}
}
if(Similar(nextVal, entry.Value, threshold))
{
if(!groups.ContainsValue(nextVal))
{
groups.Add(nextVal, nextVal);
break;
}
}
}
}
}
Out.AddRange(groups.Select(a => a.Value).ToArray(), new GH_Path(i));
}
return Out;
}
public bool Similar(double a, double b, double threshold)
{
return Math.Abs((a - b)) <= threshold;
}
Important Note: The algorithm would be much simpler if all the branches are sorted before hand. There is actually a small bug in this version because of this. So just sort the data before hand.
Another option with just gh components, use that numbers as a coordinate with [Construct Point], group them with [Points Group] component and use [List Item] to filter the numbers with the Indices output.
@Petras_Vestartas
I am asking myself the same question at the moment.
I would like to group them by their similiarity or deviations, e.g. in your first example when searching for a 0.005 devaition in
Get some entry Level take (as exposed in the SO link above - but why use floats ? [unless you have 1Z numbers on hand]). Obviously delta dictates the N of clusters (contrary to some KMeans).